Судеревская
Д.А.
Симонова
И. В.
РГПУ им.
А.И. Герцена,
г.
Санкт-Петербург
Цифровой образовательный ресурс «Обработка
естественного языка на Python» для обучения будущих учителей
В статье описан подход к обучению
основам обработки естественного языка методами машинного обучения с
использованием ЦОР, приведены результаты апробации разработанных материалов.
Suderevskaia D.A.
Irina V. Simonova
HSPU
St. Petersburg, Russia
Digital educational resource "Natural language processing in
Python" for training future teachers
The article describes an approach to teaching the
basics of natural language processing using machine learning methods using data
centers, and presents the results of testing the developed materials.
Технологии искусственного интеллекта развиваются высокими темпами
последние несколько лет, в этом ряду технологии обработки естественного языка (natural language processing или NLP) становятся одними из ведущих.
На их основе выстраиваются алгоритмы для генерации текстов, поиска ошибок в
них, определения тональности (настроения) текста, фильтрации недопустимой
информации, машинного перевода и других. Эти технологии используются в медицине,
поскольку сложные алгоритмы способны анализировать огромные массивы данных, помогая
специалистам ставить более точные диагнозы пациентам [2]. Обобщая, можно
сказать, что технологии обработки естественного языка – это технологии, которые
помогают компьютеру распознавать и понимать естественный язык.
Анализ публикаций, опыта преподавания и
широкий отклик пользователей интернета показывают, что технологии NLP, проникающие практически во все области человеческой деятельности,
необходимо изучать на всех ступенях системы образования: в школе, среднем специальном,
высшем образовании. Следовательно, актуальна подготовка и переподготовка
учителей в этом направлении. На наш взгляд, основным связующим звеном в таком
случае становятся учителя информатики [1].
Для обучения будущих учителей
информатики технологиям обработки естественного языка разработан цифровой
образовательный ресурс (далее ЦОР) – электронный курс [6], который реализован
на платформе Stepik [4].
«Цель создания электронного курса: обучение студентов старших
курсов бакалавриата работе с технологиями искусственного интеллекта для
обработки естественного языка. Задачи нами
сформулированы как повышение уровня осведомлённости студентов о возможностях
технологий искусственного интеллекта в области обработки естественного языка и
развитии у обучающихся навыков программирования и работы с библиотеками данных
для обработки естественного языка на Python» [5].
Структура ЦОР разработана с использованием
модулей, это позволяет каждому пользователю в зависимости от уровня подготовки может
усвоить содержание всех модулей или только части из них. Каждый модуль
заканчивается проверкой знаний, которая может быть реализована тестом по
основным понятиям модуля, итоговым практическим заданием (например, по
программированию), заданием на анализ учебного материала или ресурсов,
используемых в области NLP. В состав
курса включены модули, указанные в таблице 1:
Таблица 1. Состав модулей, включённых в ЦОР
|
Наименование модуля |
Темы модуля |
Примеры практических заданий и элементов контроля |
|
1.
Прежде чем начать |
Инструкция по прохождению курса |
Задания с открытым ответом для сбора данных об участниках
курса |
|
Вводное анкетирование |
Ссылка на анкету в Google Forms |
|
|
Вводное тестирование |
Ссылка на тестирование в Google Forms |
|
|
Дополнительные материалы |
Анализ данных анкеты |
|
|
2.
Введение в обработку естественного языка |
Введение |
Тестовые вопросы на выбор ответа и сопоставление,
практическое задание на совместное заполнение электронной таблицы с анализом ресурсов |
|
Установка библиотек |
Практическое задание (установка библиотеки NLTK), вопросы с открытым ответом |
|
|
3.
Алгоритмы обработки текста |
Токенизация |
Практические
задания: репродуктивные, на ручную обработку естественного языка и реализация
программы на Python с использованием библиотек NLTK. |
|
Стемминг |
||
|
Лемматизация |
||
|
Чанкинг |
||
|
Модель «Мешок слов» |
||
|
4. Проектная деятельность |
Рекомендации по выполнению задания |
Вопрос с открытым ответом, куда учащиеся записывают
выбранную тему проекта |
|
Выполнение проекта |
Вопрос с открытым ответом для загрузки ссылки на
выполненный проект |
|
|
5. Итоговая проверка знаний |
Итоговое тестирование |
Ссылка на тестирование в Google Forms |
|
Выставление оценок |
Обсуждение результатов |
|
|
Выходное анкетирование |
Ссылка на анкету в Google Forms для оценки
удовлетворённости материалами курса |
Наблюдения и анализ процесса выполнения заданий студентами показывает, что для понимания алгоритмов обработки важен этап обработки, выполненный «вручную», как это делает человек. Ниже приведён пример кодирования текста с помощью вектора для модели «Мешок слов». (Рис.1)

Рис. 1 – Пример
кодирования предложения с помощью вектора для создания «мешка слов»
Инструментарий платформы Stepik позволяет создать тестовые задания разных типов. На рисунке 2 приведём пример тестового задания.
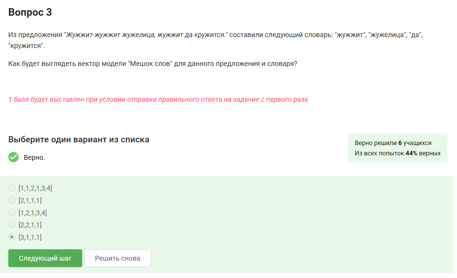
Рис. 2 – Пример
тестового задания для контроля усвоения алгоритма создания «Мешок слов», реализованного
на платформе Stepik
На
экран выводится количество учащихся, верно решивших задание и процент верных
попыток. Преподаватель в режиме реального времени может оценить результаты
выполнения заданий по следующим характеристикам:
·
ответ и его код
(загруженная ссылка, изображение, выбранный вариант ответа и др.);
·
время загрузки
ответа;
·
количество
попыток и ответ в каждой из них;
·
количество баллов
за выполнение (для заданий с автоматической проверкой);
·
количество верных
ответ и процент успешности выполнения задания.
Также
предусмотрена возможность поиска внутри списка ответов по имени,
идентификационного номеру или электронной почте пользователя, а также по коду
ответа. В качестве итогового задания студентам предлагается реализовать
программу на языке Python. Студентам предоставляется заготовка
программного кода, представленного в лекции (код заимствован из [3]). Ниже
приведён пример предложенного для обработки программного кода:
#Импортируем лемматизатор
from nltk.stem
import WordNetLemmatizer
print('\033[36m' +
'\033[1m' + '\nЛемматизация' + '\033[0m')
#Создадим переменную для лемматизатора
lemmatizer = WordNetLemmatizer()
#Создадим список исходных слов
input_words =
['printing', 'programming', 'programmer', 'computed', 'languages', 'code',
'university', 'lately', 'boring', 'funniest', 'apple', 'coding']
#Составим список вариантов лемматизаторов
lemmatizer_names = ['Noun (существительное)', 'Verb
(глагол)']
formatted_text =
'{:>30}' * (len(lemmatizer_names) + 1)
print('\n',
formatted_text.format('Исходное слово', *lemmatizer_names), '\n', '='*90)
#Лемматизация и вывод результатов
for word in input_words:
output = [word, lemmatizer.lemmatize(word,
pos='n'),
lemmatizer.lemmatize(word,
pos='v')]
print(formatted_text.format(*output))
Студентам необходимо изменить программу, используя другой набор слов (не менее 15), применить новое форматирование (значения промежутков, выравнивание, символы). В результате работы программы будет отображён следующий результат (рис. 3)
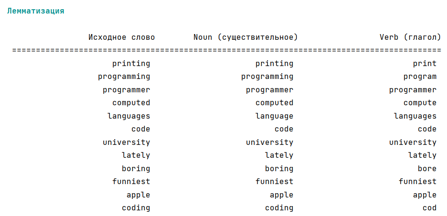
Рис. 3 – Результат
работы программы-лемматизатора
При выполнении работы студенты должны
вспомнить, что большинство библиотек для обработки естественного языка работает
с фразами на английском языке, однако в библиотеке NLTK
существует стеммер Snowball, работающий с
русским языком. Кроме того, с русскими текстами могут работать токенизаторы и
чанкеры этой библиотеки.
Учебные
материалы, разработанные и реализованные в форме ЦОР были апробированы при
проведении занятий со студентами третьего курса бакалавриата РГПУ им. А.И.
Герцена, специализирующихся в области информатики и информационных технологий в
образовании (9 человек), в рамках дополнительной программы со студентами Сахалинского
государственного университета (3 человека), со студентами магистратуры 1 курса
магистратуры РГПУ им. А.И. Герцена по программе «Цифровая образовательная среда
и цифровые технологии» (10 человек) и 2 курса магистратуры (8 человек). В общей
сложности в апробации участвовали 30 студентов. Перед началом обучения
студентам предлагалось пройти анкетирование, включающее вопросы об уровне
обучения студентов, их представлениях об обработке естественного языка, опыте
работы с электронными курсами, ожиданиях от изучения курса. Обработка
результатов анкетирования показало, что большинство студентов знакомы с темой
обработки естественного языка и изучали эту тему на занятиях. Также выяснилось,
что у всех опрошенных студентов был положительный опыт работы с платформой Stepik. Кроме того, в результате анкетирования выяснилось,
что у студентов сформированы ожидания от изучения электронного курса, что
говорит о заинтересованности в обучении. Тестирование, предложенное студентам,
показало, что все опрошенные владеют языком программирования Python на уровне не ниже среднего. Это позволило
предположить, что студенты смогут справиться с заданиями курса.
В
рамках апробации ряд студентов изучали материалы курса без контроля
преподавателя, другая группа занималась очно с преподавателем. Студенты и
первой и второй группы успешно справились с предложенными заданиями, получили
положительные отметки по результатам итогового тестирования (80%).
Вывод.
В результате апробации подтвердилась гипотеза о том, что необходимо, чтобы
студенты могли не только понимать алгоритмы и применять их на практике, но и
проникнуть глубже в суть конкретного этапа процесса обработки естественного
языка. Материалы в электронном курсе, возможно трансформировать и
модифицировать для учащихся других возрастов и направлений, что говорит о
гибкости разработанного курса.
Литература:
1. Баранова Е.В., Симонова И.В. Развитие цифровых компетенций
будущих учителей информатики при обучении алгоритмам машинного обучения и их
программной реализации //Перспективы науки. 2022. № 5 (152). С. 127-136.
2. Ваш путеводитель по миру NLP
(обработке естественного языка), Хабр, 2022. [Электронный ресурс] - Режим
доступа: https://habr.com/ru/companies/otus/articles/705482/
(дата обращения: 08.02.2024)
3. Джоши П. Искусственный
интеллект с примерами на Python: Пер. с англ.. - СПб: ООО
"Диалектика", 2019. - 448 с.
4. Платформа Stepik.
URL: https://stepik.org/
(дата обращения: 08.02.2024)
5. Судеревская Д.А. Модель
электронного учебного курса для обучения будущих учителей информатики
технологиям обработки естественного языка//Новые образовательные стратегии в
современном информационном пространстве: сборник научных статей по материалам
международной научно-практической конференции, Санкт-Петербург, 9–29 марта 2023
г.. - СПб.: Астерион, 2023. - С. 88-93.
6. Электронный курс «Обработка естественного языка
на Python» [Электронный ресурс] - Режим доступа: https://stepik.org/course/134179/syllabus
(дата обращения: 08.02.2024)